Spring
Spring Batch - ItemWriter
- -
ItemWriter
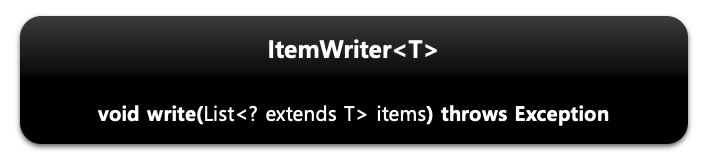
- Chunk 단위로 데이터를 받아 일괄 출력 작업을 위한 인터페이스입니다.
- 플랫 파일 - csv, txt
- XML, Jsono
- Database
- Message Queuing 서비스
- Mail Service
- Custom reader
- 다수의 구현체들이 itemReader와 같은 맥락으로 itemWriter와 ItemStream을 동시에 구현하고 있습니다.
- 하나의 아이템이 아닌 아이템 리스트를 전달받아 수행합니다.
- ChunkOrientedTasklet 실행 시 필수적 요소로 설정해야 합니다.
- void write()
- 출력 데이터를 아이템 리스트로 받아서 처리합니다.
- 출력이 완료되고 트랜잭션이 종료되면 새로운 Chunk 단위 프로세스로 이동합니다.

위와 같이 다양한 구현체들을 제공하고 있습니다.
JdbcBatchItemWriter
Jdbc Batch 기능을 사용하여 Bulk insert/update/delete 방식으로 처리합니다. Bulk 처리로 단건 처리가 아닌 일괄 처리이기 때문에 성능에 이점을 갖습니다.
API

Mapped는 둘 중에 하나만 사용할 수 있습니다. beanMapped는 ItemWriter로 넘어오는 객체의 필드 기반으로 sql 데이터 바인딩이 진행됩니다. columnMapped는 ItemWriter로 넘어오는 것이 객체가 아닌 Map 컬렉션으로 넘길 때 사용합니다. Map 컬렉션의 데이터들이 sql에 바인딩됩니다.
예시
@Slf4j
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private int chunkSize = 10;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step")
.<Customer, Customer>chunk(chunkSize)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<Customer> customItemReader() {
Map<String, Object> parameters = new HashMap<>();
parameters.put("age",25);
return new JpaPagingItemReaderBuilder<Customer>()
.name("jpaPagingItemReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(10)
.queryString("select c from Customer c where age >= :age order by c.id")
.parameterValues(parameters)
.build();
}
@Bean
public ItemWriter<Customer> customItemWriter() {
return new JdbcBatchItemWriterBuilder<Customer>()
.dataSource(dataSource)
.sql("insert into customer2 values (:id, :age, :name)")
.beanMapped()
.build();
}
}
Customer를 읽어서 이름만 다른 Customer2에 쓰는 작업입니다. beanMapped API를 사용하면 Customer 객체 기반으로 쿼리의 values에 파라미터가 알아서 매핑됩니다.
JpaItemWriter
- JPA 엔티티 기반으로 데이터를 처리합니다.
- 엔티티를 하나씩 청크 크기만큼 insert 혹은 merge 한 다음 flush 합니다.
- insert 쿼리가 하나씩 나가기 때문에 JPA 벌크 insert를 하기 위해서는 rewriteBatchedStatements 옵션과 Table 전략 등 따로 세팅이 필요합니다.
- ItemReader나 ItemProcessor로부터 아이템을 전달받을 때는 쓰기 할 엔티티 클래스 타입 자체를 받아야 합니다.
API

엔티티 자체를 바로 저장하기 때문에 쿼리문이 따로 필요 없습니다. spring batch에서 JpaItemWriter를 통한 write 작업은 신규 생성되는 Entity를 저장하는 기능과 기존 Entity의 값을 변경하는 두 방식에 대해 모두 대응해야 하기 때문에 Merge가 기본값으로 들어가면서 usePersist의 기본값은 false입니다. 따라서 JpaItemWriter가 save 하는 시점에는 select를 먼저 호출하고 insert를 수행하게 됩니다. 즉, 신규 Entity를 만들어내는 Job이라면 불필요한 select문을 줄이기 위해 usePersist 옵션을 true로 지정해야 합니다.
예시
@Slf4j
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private int chunkSize = 10;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step")
.<Customer, Customer2>chunk(chunkSize)
.reader(customItemReader())
.processor(customItemProcessor())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<Customer> customItemReader() {
Map<String, Object> parameters = new HashMap<>();
parameters.put("age",25);
return new JpaPagingItemReaderBuilder<Customer>()
.name("jpaPagingItemReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(10)
.queryString("select c from Customer c where age >= :age order by c.id")
.parameterValues(parameters)
.build();
}
@Bean
public ItemProcessor<Customer, Customer2> customItemProcessor() {
return new ItemProcessor<Customer, Customer2>() {
@Override
public Customer2 process(Customer item) throws Exception {
return new Customer2(item);
}
};
}
@Bean
public ItemWriter<Customer2> customItemWriter() {
return new JpaItemWriterBuilder<Customer2>()
.entityManagerFactory(entityManagerFactory)
.build();
}
}
프로세서를 이용해서 중간에 customer를 customer2로 만들어서 writer로 넘겨서 저장하는 예시입니다.
ItemWriterAdapter
배치 Job 안에 이미 있는 DAO나 다른 서비스를 ItemWriter 안에서 사용하고자 할 때 위임하는 기능을 합니다.
@Slf4j
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private final DataSource dataSource;
private int chunkSize = 10;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step")
.<Customer, Customer>chunk(chunkSize)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<Customer> customItemReader() {
Map<String, Object> parameters = new HashMap<>();
parameters.put("age", 25);
return new JpaPagingItemReaderBuilder<Customer>()
.name("jpaPagingItemReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(10)
.queryString("select c from Customer c where age >= :age order by c.id")
.parameterValues(parameters)
.build();
}
@Bean
public ItemWriter<Customer> customItemWriter() {
ItemWriterAdapter<Customer> writer = new ItemWriterAdapter<>();
writer.setTargetObject(customService()); // 대상 클래스
writer.setTargetMethod("customWrite"); // 대상 메서드
return writer;
}
@Bean
public CustomService customService() {
return new CustomService();
}
}
----------------------------------------------------------
public class CustomService<T> {
public void customWrite(T item){
System.out.println("item = " + item);
}
}
writer에서 대상 클래스 메서드의 인자로 item들을 묶은 청크단위의 List가 넘어가는 게 아니라 하나씩의 item이 넘어갑니다.
같은 조건의 데이터를 읽고 수정할 때
Pay 엔티티의 상태가 false인 50개의 데이터를 배지 작업에서 상태를 true로 바꾸고 writer에서 update 하는 작업을 한다고 가정해 보겠습니다.
@Slf4j
@RequiredArgsConstructor
@Configuration
public class PayPagingFailJobConfiguration {
public static final String JOB_NAME = "payPagingFailJob";
private final EntityManagerFactory entityManagerFactory;
private final StepBuilderFactory stepBuilderFactory;
private final JobBuilderFactory jobBuilderFactory;
private final int chunkSize = 10;
@Bean
public Job payPagingJob() {
return jobBuilderFactory.get(JOB_NAME)
.start(payPagingStep())
.build();
}
@Bean
@JobScope
public Step payPagingStep() {
return stepBuilderFactory.get("payPagingStep")
.<Pay, Pay>chunk(chunkSize)
.reader(payPagingReader())
.processor(payPagingProcessor())
.writer(writer())
.build();
}
@Bean
@StepScope
public JpaPagingItemReader<Pay> payPagingReader() {
return new JpaPagingItemReaderBuilder<Pay>()
.queryString("SELECT p FROM Pay p WHERE p.successStatus = false")
.pageSize(chunkSize)
.entityManagerFactory(entityManagerFactory)
.name("payPagingReader")
.build();
}
@Bean
@StepScope
public ItemProcessor<Pay, Pay> payPagingProcessor() {
return item -> {
item.success();
return item;
};
}
@Bean
@StepScope
public JpaItemWriter<Pay> writer() {
JpaItemWriter<Pay> writer = new JpaItemWriter<>();
writer.setEntityManagerFactory(entityManagerFactory);
return writer;
}
}
배치 작업을 돌려보면 50개의 데이터가 배치작업이 되어있지 않을 것입니다. 10개씩 Chunk 단위로 작업을 진행하면 첫 번째 쿼리는 offset 0 limit 10 이지만 두번째 쿼리부터는 offset 11 limit 10이 나가게 되기 때문입니다. 첫번째 Chunk 작업에서 10개의 데이터가 success로 변경되었기 때문에 다시 쿼리가 나갈 때는 offset을 0부터 해야 합니다. 따라서 이때는 JpaPagingItemReader의 getPage 메서드를 override 해서 수정해주어야 합니다.
@Bean
@StepScope
public JpaPagingItemReader<Pay> payPagingReader() {
JpaPagingItemReader<Pay> reader = new JpaPagingItemReader<Pay>() {
@Override
public int getPage() {
return 0;
}
};
reader.setQueryString("SELECT p FROM Pay p WHERE p.successStatus = false");
reader.setPageSize(chunkSize);
reader.setEntityManagerFactory(entityManagerFactory);
reader.setName("payPagingReader");
return reader;
}
ItemWriter에 List 전달하기
Processor에서 List형태로 반환하게 되면 Writer는 이걸 바로 해결할 수 없습니다. 만약 청크 사이즈가 10이라면 10개의 리스트를 하나의 리스트 안에 담아서 itemWriter에 넘기게 됩니다. 따라서 itemWriter의 Write 메서드를 재정의하여 하나의 리스트로 풀어주고 해당 데이터를 write 하는 과정으로 수정해야 합니다.
public class JpaItemListWriter<T> extends JpaItemWriter<List<T>> {
private JpaItemWriter<T> jpaItemWriter;
public JpaItemListWriter(JpaItemWriter<T> jpaItemWriter) {
this.jpaItemWriter = jpaItemWriter;
}
@Override
public void write(List<? extends List<T>> items) {
List<T> totalList = new ArrayList<>();
for (List<T> list: items) {
totalList.addAll(list);
}
jpaItemWriter.write(totalList);
}
}
write를 재정의해서 전달받은 데이터의 리스트를 풀어서 하나의 리스트에 담고 기존 jpaItemWriter에게 쓰기 작업을 다시 시킨 코드입니다. Job에 적용할 때는 아래와 같이 하면 됩니다.
@Configuration
@RequiredArgsConstructor
public class SimpleJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private int chunkSize = 10;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.incrementer(new RunIdIncrementer())
.start(step())
.build();
}
public Step step() {
return stepBuilderFactory.get("step")
.<Customer, List<Customer2>>chunk(chunkSize)
.reader(customItemReader())
.processor(customItemProcessor())
.writer(customItemWriter())
.build();
}
@Bean
public JpaPagingItemReader<Customer> customItemReader() {
return new JpaPagingItemReaderBuilder<Customer>()
.name("customItemReader")
.pageSize(chunkSize)
.entityManagerFactory(entityManagerFactory)
.queryString("select c from Customer c order by c.id")
.build();
}
@Bean
public ItemProcessor<Customer, List<Customer2>> customItemProcessor() {
return item -> Arrays.asList(new Customer2(item.getName(), item.getAge()));
}
@Bean
public JpaItemListWriter<Customer2> customItemWriter() {
JpaItemWriter<Customer2> writer = new JpaItemWriter<>();
writer.setEntityManagerFactory(entityManagerFactory);
JpaItemListWriter<Customer2> jpaItemListWriter = new JpaItemListWriter<>(writer);
jpaItemListWriter.setEntityManagerFactory(entityManagerFactory);
return jpaItemListWriter;
}
}'Spring' 카테고리의 다른 글
| Spring Batch - 반복 및 오류 제어 (0) | 2024.01.31 |
|---|---|
| Spring Batch - ItemProcessor (0) | 2024.01.28 |
| Spring Batch - ItemReader (0) | 2024.01.28 |
| Spring Batch - 청크 기반 프로세스 (0) | 2024.01.25 |
| Spring Batch - DB 스키마와 도메인 (0) | 2024.01.24 |
Contents
소중한 공감 감사합니다